What is a Robots.txt File?
Robots.txt is a plain text file located in the root directory of a website. Its primary function is to instruct web robots (a.k.a crawlers or spiders) on how to interact with the website. The "Robots Exclusion Protocol" it uses offers a series of directions to inform search engine bots about which pages they can or cannot visit.
Consider the robots.txt file as a gatekeeper of your site who controls the entry and exit of unwanted guests, ensuring that the important elements of your website get the attention they deserve.
Why is Robots.txt Important?
Now, you might be asking yourself why learning about the robots.txt file matters to you as a marketer or SEO expert. Here are the key reasons:
Search Engine Indexing: Robots.txt can guide search engines to your website's key pages, improving your visibility in the SERP(Search Engine Result Pages).
Crawl Budget Optimization: A robots.txt file can effectively optimize your crawl budget by preventing search engine bots from wasting time on irrelevant web pages.
Protection of Sensitive Data: If your site holds any private data or content that should never be publicly viewable, a robots.txt file can be a barricade.
Remember, an incorrect robots.txt setup can bar search engine bots from indexing your site altogether, affecting your SEO. Hence, mastering robots.txt is crucial.
How Does a Robots.txt File Work?
The working principle of a robots.txt file is fairly simple. When a search engine bot tries to access a webpage, it first checks the robots.txt file in the root directory. If the crawler is allowed, it proceeds to index that page.
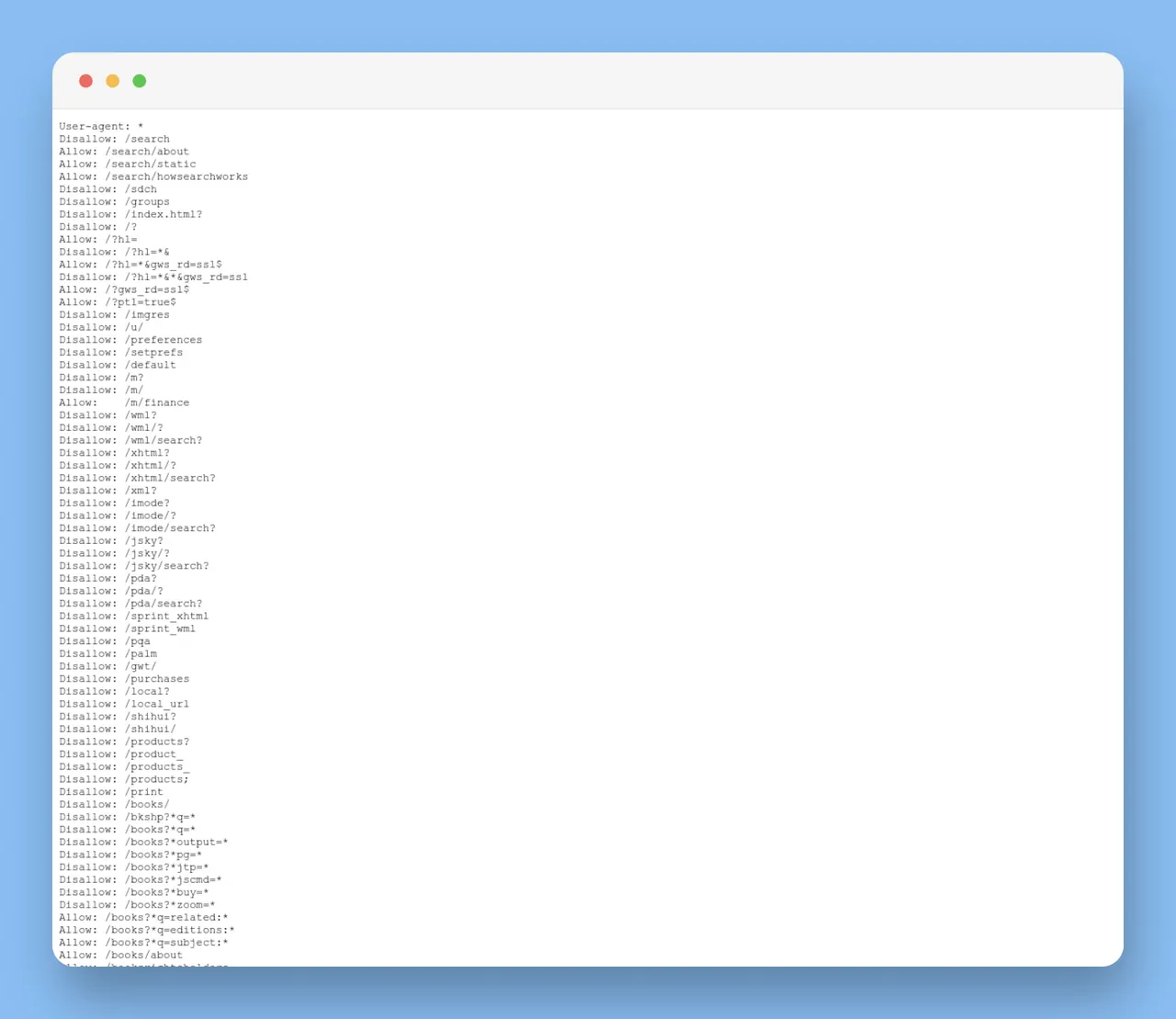
The structure of a robots.txt file usually consists of "User-agent" followed by "Disallow" or "Allow" directives.
- User-agent: This is the web crawler that the rule applies to.
- Disallow: The instruction telling the user-agent not to crawl a particular URL.
- Allow: The directive that permits user-agents to crawl a URL (used mainly for granting access to subdirectories in an otherwise disallowed directory).
In the next section, we will delve deeper into these directives and others, giving you a better understanding of the terminology and syntax used in Robots.txt files.
Time to don your programmer hat and march on this fascinating journey of demystifying the robots.txt file, one of the cornerstones of successful SEO.
For further reading, visit Google's guide to robots.txt.
Understanding the Terminology and Syntax
To truly master the robots.txt guide, you need to understand its vocabulary. Hang on tight as we demystify the terminology and syntax of the robots.txt file.
The User-Agent Directive
The User-Agent is at the heart of any robots.txt file. It's like the main character of our story, around which all the rules revolve.
A User-agent in the context of a robots.txt file is nothing but a search engine bot. Some commonly known User-agents include Googlebot for Google and Bingbot for Bing.
The User-Agent line in the robots.txt file is written as -
User-agent: [name-of-the-crawler]
For instance, if you want to address Google's crawler, the User-agent will look like this:
User-agent: Googlebot
On the other hand, when you want all bots to follow the set of directives, you'd use an asterisk (*) like so:
User-agent: *
The Disallow Directive
After specifying our protagonist, the User-agent, it's time to lay down some ground rules. That's where the Disallow directive comes into play.
The Disallow directive tells the bot what path it should not crawl or index. If you want to prevent search engine crawlers from accessing a specific page, you will use Disallow.
Here's what a Disallow directive looks like:
Disallow: /page-link/
The Allow Directive
Sometimes, we want to allow certain exceptions, and that is where the Allow rule comes in handy.
Allow is particularly useful when you want to grant access to a particular subdirectory or page in an otherwise disallowed directory.
Consider the following example:
User-agent: *
Disallow: /folder/
Allow: /folder/important-page.html
In this case, the general rule is not to access /folder/, but there's an exception important-page.html which is allowed to be crawled and indexed.
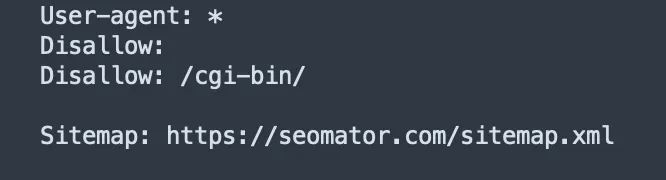
The Sitemap Directive
This directive makes it easier for search engines to find your sitemap. Sitemap URLs are written on individual lines preceded by 'Sitemap':
Sitemap: https://www.yourwebsite.com/sitemap.xml
Use Wildcards to Clarify Directions
You can use the * wildcard character in Disallow and Allow directives to match any sequence of characters. For example:
Disallow: /*? Disallows any URLs that include a ? .
Use '$' to Indicate the End of a URL
If you want to match a specific file type or to avoid ambiguity in URLs, use the dollar sign ($) at the end of the URL. For example, Disallow: /*.jpg$ will disallow all .jpg files.
Hash symbols can be used for comments for your future reference. For example:
# Blocks access to all subdirectories under /private/
Disallow: /private
In the world of robots.txt files, mastering the syntax and jargon is everything. The clarity of syntax in your Robots.txt file can make or break your site's SEO performance.
And hey, great job so far! You are absorbing some truly technical stuff. Keep going, champ! Up next, we will unravel the true function of a robots.txt file!
The Function of a Robots.txt File
Now that we have explored what a robots.txt file is and familiarized ourselves with its syntax, it's time to delve deeper and understand the real-world functions of robots.txt.
A robots.txt file is not just a set of rules you impose on search engines–it’s a practical tool that touches upon various parts of website management and optimization. Let's look at some ways this advantageous file can be deployed.

Optimize Crawl Budget
Let's start with an interesting term–Crawl Budget. It refers to the number of pages a search engine crawler can and wants to crawl. Every website has a crawl budget assigned by search engines, and efficiently using this budget is key for website optimization.
Too many unimportant or irrelevant pages can clog your website, making it difficult for search crawlers to access the essential components. The robots.txt file lets these crawlers know which areas they can skip, thereby saving your crawl budget for important pages.
In a nutshell–the more efficiently your crawl budget is used, the faster your new or updated content will get indexed, a key factor in achieving higher rankings on SERPs.
Block Duplicate and Non-Public Pages
Often a website has pages that are necessary for functionality but not meant for public viewing or indexing. These could include admin pages, backend files, or pages with duplicate content. This is where robots.txt comes in.
By deploying the Disallow directive, you can prevent crawlers from accessing these areas. Doing this ensures that only unique and necessary content appears on SERPs, enhancing your online reputation by avoiding potential penalties for duplicate or thin content.
Hide Resources
The internet, as we know, is an open book. But not all chapters of this book are meant for everyone. Some resources or content are meant for internal use only–like internal files, data, images, etc. A well-crafted robots.txt file can prevent Google and other search engines from accessing and listing such material in search results.
It’s very important to note that robots.txt is not a security measure. While it can prevent respectable search engines from displaying certain URLs in their results, it does not prevent other users from accessing these URLs. For secure content, always use proper password protection or other security measures.
Now that we have delved deep into the functions of a robots.txt file, let us move onto the next phase of our journey: Creating and Implementing a Robots.txt File. Take a deep breath, grab your cup of coffee and let's keep the momentum going!
As always, if you'd like to learn more, check out Google's official documentation on Robots Meta tags and Headers for advanced insights.
Creating and Implementing a Robots.txt File
The creation and implementation of a robots.txt file may seem intimidating, especially if you're not particularly tech-savvy. But don't panic! We're right here with you every step of the way. We'll make this process as straightforward as possible by breaking it down into simple steps.
Create a File and Name It Robots.txt
Start by creating a new text file. You can do this with any simple text editor like Notepad (Windows) or TextEdit (Mac). Once you have a blank document open, save the file as robots.txt. Make sure it's all lowercase, because Robots.txt, ROBOTS.TXT, or any other capitalization will not be recognized.
Add Directives to the Robots.txt File
Think about what you want to allow or disallow, and start entering directives based on this. Here’s a very basic example:
User-agent: *
Disallow: /private/
This tells all bots (because of the * wildcard) not to crawl anything under the /private/ directory.
Upload the Robots.txt File
Once your robots.txt file is ready, you need to upload it to the root directory of your website. This is typically the same place where your website's main index.html file is located.Remember, the robots.txt file must be placed at the root (e.g., www.yourwebsite.com/robots.txt) to be found and recognized by bots.
How to Find a Robots.txt File
To see if a robots.txt file is in place or access yours, simply type /robots.txt at the end of your website’s main URL in your web browser.
Test Your Robots.txt
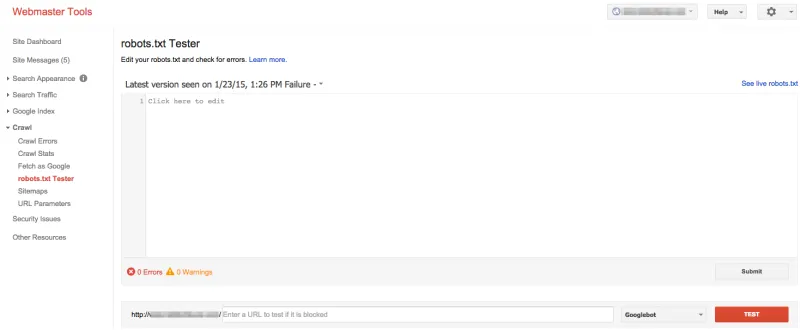
Finally, it's highly recommended to test your robots.txt file to ensure it’s working as expected. SEOmator provides a great Robots.txt Tester Tool that you can comfortably use.
Well done on creating your first robots.txt file! You're officially on your way to mastering this essential side of website management and SEO.
And remember, the more you learn, the better your overall SEO skills will be. So don't shy away from challenging yourself. Because as they say, learning never exhausts the mind. Keep going!
Insight Into Robots.txt Best Practices
With the knowledge of creating and implementing a robots.txt file under your belt, let's refine that knowledge with some important best practices. These will ensure you're not only following the rules but doing so effectively.
So tighten your seat belt, dear reader, as we sail into the universe of Robots.txt's best practices. Your mastery of robots.txt is just around the corner!
Don’t Block CSS and JS Files in Robots.txt
One key insight for making the most out of your robots.txt file is to avoid blocking JavaScript and CSS files. These files are essential for Googlebots to understand your website content and structure effectively.
Previously, blocking such files wasn't seen as an issue, but as Googlebots evolved to render pages more like a human visitor, they now need access to these files to enhance the analysis of the webpage.
Adding CSS or JS files to the Disallow directive could result in suboptimal rankings as Google may not fully understand your page layout or its interactive elements. So remember, let the bots enjoy the JavaScript and CSS party on your website!
Use Separate Robots.txt Files for Different Subdomains
If your website has multiple subdomains, you need to remember that each subdomain requires its own robots.txt file. For example, if you have a blog on a subdomain (like blog.yourwebsite.com), you need a separate robots.txt file at blog.yourwebsite.com/robots.txt.
This is because search engine crawlers treat subdomains as separate websites. Overlooking this detail could lead to misunderstandings by bots, which might crawl or not crawl areas of your site contrary to your intentions.
SEO Best Practices for Robots.txt
In the grand scheme of SEO, your robots.txt file plays a critical role. Here are a few SEO-focused best practices for robots.txt:
Avoid Blocking Search Engines Entirely: Blocking all search engine bots can result in your site not being indexed at all. Use Disallow judiciously and only for specific parts of your site that you do not want to be indexed.
Don't use it for URL Removal: If you want a URL to be removed from search engine results, using robots.txt to disallow that URL isn't the best way, as it can still appear in the results due to external links pointing to it. Instead, use methods like the “noindex”, "remove URLs tool", or password protection.
Link to your XML Sitemap: An excellent practice is to use robots.txt to link to your XML Sitemap. This increases the chances of bots finding your sitemap and thus, indexing your pages faster.
Applying these best practices will ensure that your robots.txt file serves as a helping hand to your SEO strategies, not a hindrance.
Kudos to you, dear reader! You've made it through some of the more advanced aspects of robots.txt files. Stay enthusiastic, keep the curiosity alive, and let's move on to wrap up this comprehensive guide on robots.txt!
And as always, for more in-depth information and guidance, be sure to check out Google's official resources. Happy reading!
Conclusion: The Integral Role of Robots.txt in SEO
Our journey into the deep seas of robots.txt brings us to the concluding thoughts. You’ve learned what robots.txt is, its importance, its working mechanism, the directives and syntax, and its creation and implementation. We have also covered practical uses and best practices.
Let’s reiterate the significant parts and look at the pros and cons of using robots.txt, its impact on your crawl budget and SEO, and the foreseeable future directions in robots.txt usage.
Pros and Cons of Using Robots.txt
Like all optimization strategies, robots.txt comes with its advantages and potential pitfalls:
Pros:
- Control Over Crawling: robots.txt gives you a simple way to direct bots where they should and shouldn't go on your site.
- Crawl Budget Optimization: It enables the efficient use of your crawl budget by guiding crawlers to the important areas of your website.
- Avoiding Indexing of Non-Public Areas: You can prevent certain areas of your site from being indexed.
Cons:
- Not Legally Binding: Bots can ignore your robots.txt–especially malware bots that scan for weaknesses on your site.
- Can Cause Crawlability Issues: In cases of misconfiguration, you can accidentally block bots from crawling your site.
The Impact of Robots.txt on Crawl Budget and SEO
A well-structured robots.txt file has a profound impact on your site’s crawl budget and SEO. By allowing crawlers to focus on areas of your site that deserve the most attention, you’re helping to ensure that your site is crawled effectively and efficiently, maximizing the chance for higher rankings.
Future Directions in Robots.txt Usage
Google's robots directive is constantly evolving and striving for better comprehension and more comprehensive coverage. In the future, we anticipate more precise syntax, better directives, improved support for international URLs, and an ever-greater understanding of what website owners need.
Phew! You did it! You've now mastered robots.txt, and are set to optimize your website for smooth crawling and indexing by search engine bots.
Congratulations, dear reader, for making it to the end of this comprehensive robots.txt guide. Your determination, your willingness to learn, and your newfound knowledge of robots.txt files will certainly drive your SEO efforts to new heights.
Remember, knowledge is power, and you've just become more powerful! Good job, and keep going!
P.S: Enjoyed your journey? Keep exploring. SEO is a vast ocean, and there's always more to learn!
You May Also Read:





