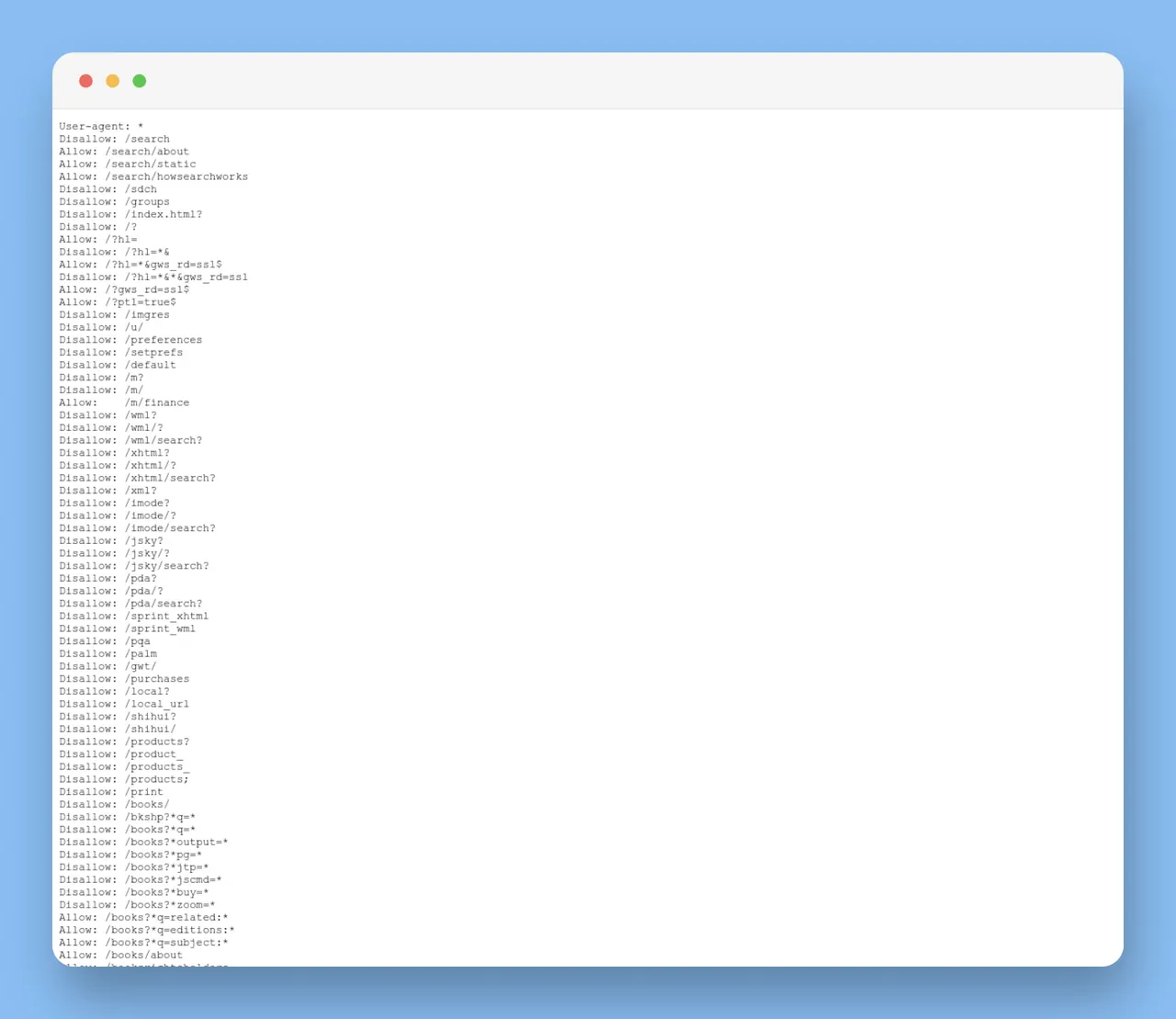
Was ist eine Robots.txt-Datei?
Robots.txt ist eine einfache Textdatei, die sich im Stammverzeichnis einer Website befindet. Ihre Hauptfunktion besteht darin, Web-Robots (auch Crawler oder Spider genannt**)** zu instruieren, wie sie mit der Website interagieren sollen. Das darin verwendete "Robots Exclusion Protocol" bietet eine Reihe von Anweisungen, um Suchmaschinen-Bots darüber zu informieren, welche Seiten sie besuchen können und welche nicht.
Betrachten Sie die robots.txt-Datei als einen Torwächter Ihrer Website, der den Ein- und Austritt unerwünschter Gäste kontrolliert und sicherstellt, dass die wichtigen Elemente Ihrer Website die Aufmerksamkeit erhalten, die sie verdienen.
Warum ist Robots.txt wichtig?
Vielleicht fragen Sie sich jetzt, warum es für Sie als Vermarkter oder SEO-Experte wichtig ist, etwas über die robots.txt-Datei zu erfahren. Hier sind die wichtigsten Gründe:
Indizierung durch Suchmaschinen: Robots.txt kann Suchmaschinen zu den wichtigsten Seiten Ihrer Website leiten und so Ihre Sichtbarkeit in den SERP (Search Engine Result Pages) verbessern.
Crawl-Budget-Optimierung: Eine robots.txt-Datei kann Ihr Crawl-Budget effektiv optimieren, indem sie verhindert, dass Suchmaschinen-Bots Zeit auf irrelevanten Webseiten verschwenden.
Schutz von sensiblen Daten: Wenn Ihre Website private Daten oder Inhalte enthält, die niemals öffentlich einsehbar sein sollten, kann eine robots.txt-Datei eine Barrikade sein.
Denken Sie daran, dass eine fehlerhafte robots.txt-Einstellung Suchmaschinenbots daran hindern kann, Ihre Website zu indizieren, was sich auf Ihre Suchmaschinenoptimierung auswirkt. Daher ist die Beherrschung von robots.txt entscheidend.
Wie funktioniert eine robots.txt-Datei?
Das Funktionsprinzip einer robots.txt-Datei ist recht einfach. Wenn ein Suchmaschinen-Bot versucht, auf eine Webseite zuzugreifen, überprüft er zunächst die robots.txt-Datei im Stammverzeichnis. Wird der Crawler zugelassen, fährt er mit der Indizierung der Seite fort.
Die Struktur einer robots.txt-Datei besteht in der Regel aus "User-agent", gefolgt von "Disallow"- oder "Allow"-Anweisungen.
-
Benutzer-Agent: Dies ist der Web-Crawler, für den die Regel gilt.
-
Nicht zulassen: Die Anweisung, die den User-Agent anweist, eine bestimmte URL nicht zu crawlen.
-
Zulassen: Die Anweisung, die es Benutzer-Agenten erlaubt, eine URL zu crawlen (wird hauptsächlich verwendet, um den Zugriff auf Unterverzeichnisse in einem ansonsten verbotenen Verzeichnis zu gewähren).
Im nächsten Abschnitt werden wir diese und andere Direktiven näher erläutern, um Ihnen ein besseres Verständnis der in Robots.txt-Dateien verwendeten Terminologie und Syntax zu vermitteln.
Setzen Sie Ihren Programmiererhut auf und begeben Sie sich auf diese faszinierende Reise zur Entmystifizierung der robots.txt-Datei, einem der Eckpfeiler erfolgreicher Suchmaschinenoptimierung.
Weitere Informationen finden Sie in Googles Leitfaden zu robots.txt.
Verstehen der Terminologie und Syntax
Um die robots.txt-Anleitung wirklich zu beherrschen, müssen Sie ihr Vokabular verstehen. Halten Sie sich fest, während wir die Terminologie und Syntax der robots.txt-Datei entmystifizieren .
Die User-Agent-Richtlinie
Der Benutzer-Agent ist das Herzstück einer jeden robots.txt-Datei. Er ist so etwas wie die Hauptfigur in unserer Geschichte, um die sich alle Regeln drehen.
Ein User-Agent im Zusammenhang mit einer robots.txt-Datei ist nichts anderes als ein Suchmaschinen-Bot. Zu den allgemein bekannten User-Agents gehören Googlebot für Google und Bingbot für Bing.
Die User-Agent-Zeile in der robots.txt-Datei wird wie folgt geschrieben
Benutzer-Agent: [Name des Crawlers]
Wenn Sie zum Beispiel den Crawler von Google ansprechen möchten, sieht der User-Agent wie folgt aus:
Benutzer-Agent: Googlebot
Wenn Sie hingegen möchten, dass alle Bots den Richtlinien folgen, verwenden Sie ein Sternchen (*) wie folgt:
Benutzer-Agent: *
Die Disallow-Richtlinie
Nachdem wir unseren Protagonisten, den Benutzer-Agenten, festgelegt haben, ist es an der Zeit, einige Grundregeln festzulegen. An dieser Stelle kommt die Disallow-Anweisung ins Spiel.
Die Disallow-Direktive teilt dem Bot mit, welchen Pfad er nicht crawlen oder indizieren soll. Wenn Sie Suchmaschinen-Crawler daran hindern wollen, auf eine bestimmte Seite zuzugreifen, verwenden Sie Disallow.
So sieht eine Disallow-Direktive aus:
Disallow: /page-link/
Die Allow-Direktive
Manchmal wollen wir bestimmte Ausnahmen zulassen, und da kommt die Allow-Regel gerade recht.
Allow ist besonders nützlich, wenn Sie den Zugriff auf ein bestimmtes Unterverzeichnis oder eine Seite in einem ansonsten verbotenen Verzeichnis erlauben wollen.
Betrachten Sie das folgende Beispiel:
Benutzer-Agent: *
Nicht zulassen: /Ordner/
Erlaubt: /ordner/wichtige-seite.html
In diesem Fall gilt die allgemeine Regel, dass der Zugriff auf /folder/ nicht erlaubt ist, aber es gibt eine Ausnahme important-page.html, die gecrawlt und indiziert werden darf.
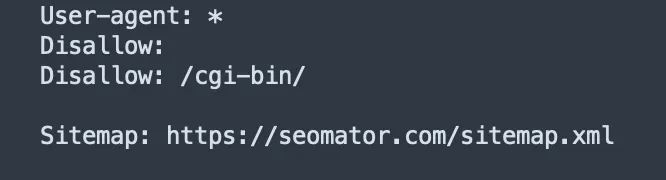
Die Sitemap-Richtlinie
Diese Richtlinie erleichtert es den Suchmaschinen, Ihre Sitemap zu finden. Sitemap-URLs werden in einzelne Zeilen geschrieben, denen ein "Sitemap" vorangestellt wird:
Sitemap: https://www.yourwebsite.com/sitemap.xml
Verwendung von Platzhaltern zur Verdeutlichung von Richtungen
Sie können das Platzhalterzeichen * in den Disallow- und Allow-Direktiven verwenden, um eine beliebige Folge von Zeichen zu finden. Zum Beispiel:
Disallow: /*? Verbietet alle URLs, die ein ? enthalten.
Verwenden Sie '$', um das Ende einer URL zu kennzeichnen
Wenn Sie einen bestimmten Dateityp abgleichen oder Mehrdeutigkeiten in URLs vermeiden möchten, verwenden Sie das Dollarzeichen ($) am Ende der URL. Zum Beispiel: Disallow: /*.jpg$ lässt alle .jpg-Dateien nicht zu.
Verwenden Sie die Raute (#), um Kommentare hinzuzufügen
Rautensymbole können für Kommentare verwendet werden, auf die Sie später zurückgreifen können. Zum Beispiel:
# Sperrt den Zugriff auf alle Unterverzeichnisse unter /private/
Nicht zulassen: /privat
In der Welt der robots.txt-Dateien ist die Beherrschung der Syntax und des Fachjargons das A und O. Die Klarheit der Syntax in Ihrer Robots.txt-Datei kann über die SEO-Leistung Ihrer Website entscheiden.
Und hey, tolle Arbeit bis jetzt! Sie haben sich ein paar wirklich technische Dinge angeeignet. Mach weiter so, Champion! Als Nächstes werden wir die wahre Funktion einer robots.txt-Datei enträtseln!
Die Funktion einer robots.txt-Datei
Nachdem wir nun herausgefunden haben, was eine robots.txt-Datei ist, und uns mit ihrer Syntax vertraut gemacht haben, ist es an der Zeit, tiefer zu gehen und die tatsächlichen Funktionen von robots.txt zu verstehen.
Eine robots.txt-Datei ist nicht nur eine Reihe von Regeln, die Sie den Suchmaschinen auferlegen, sondern ein praktisches Werkzeug, das verschiedene Bereiche der Website-Verwaltung und -Optimierung berührt. Sehen wir uns einige Möglichkeiten an, wie diese vorteilhafte Datei eingesetzt werden kann.

Crawl-Budget optimieren
Beginnen wir mit einem interessanten Begriff: Crawl-Budget. Er bezieht sich auf die Anzahl der Seiten, die ein Suchmaschinen-Crawler crawlen kann und will. Jede Website hat ein Crawl-Budget, das von den Suchmaschinen zugewiesen wird, und die effiziente Nutzung dieses Budgets ist der Schlüssel zur Optimierung der Website.
Zu viele unwichtige oder irrelevante Seiten können Ihre Website verstopfen und es den Suchmaschinen-Crawlern erschweren, auf die wesentlichen Komponenten zuzugreifen. Die robots.txt-Datei teilt diesen Crawlern mit, welche Bereiche sie überspringen können, und spart so Ihr Crawl-Budget für wichtige Seiten.
Kurz gesagt: Je effizienter Ihr Crawl-Budget genutzt wird, desto schneller werden Ihre neuen oder aktualisierten Inhalte indiziert - ein Schlüsselfaktor für bessere Platzierungen in den SERPs.
Blockieren Sie doppelte und nicht-öffentliche Seiten
Oft gibt es auf einer Website Seiten, die für die Funktionalität notwendig sind, aber nicht für die öffentliche Ansicht oder Indizierung bestimmt sind. Dazu können Verwaltungsseiten, Backend-Dateien oder Seiten mit doppeltem Inhalt gehören. Hier kommt robots.txt ins Spiel.
Durch den Einsatz der Disallow-Direktive können Sie Crawler am Zugriff auf diese Bereiche hindern. Auf diese Weise wird sichergestellt, dass nur einzigartige und notwendige Inhalte in den SERPs angezeigt werden, was Ihren Online-Ruf stärkt, da Sie potenzielle Strafen für doppelte oder dünne Inhalte vermeiden.
Ressourcen verstecken
Das Internet ist, wie wir wissen, ein offenes Buch. Aber nicht alle Kapitel dieses Buches sind für jedermann bestimmt. Einige Ressourcen oder Inhalte sind nur für den internen Gebrauch bestimmt - wie interne Dateien, Daten, Bilder usw. Eine gut ausgearbeitete robots.txt-Datei kann Google und andere Suchmaschinen daran hindern, auf solches Material zuzugreifen und es in den Suchergebnissen aufzuführen.
Es ist sehr wichtig zu beachten, dass robots.txt keine Sicherheitsmaßnahme ist. Sie kann zwar seriöse Suchmaschinen daran hindern, bestimmte URLs in ihren Ergebnissen anzuzeigen, verhindert aber nicht, dass andere Nutzer auf diese URLs zugreifen. Für sichere Inhalte sollten Sie immer einen angemessenen Passwortschutz oder andere Sicherheitsmaßnahmen verwenden.
Nachdem wir uns nun eingehend mit den Funktionen einer robots.txt-Datei befasst haben, wollen wir nun zur nächsten Phase unserer Reise übergehen: Erstellen und Implementieren einer robots.txt-Datei. Atmen Sie tief durch, schnappen Sie sich eine Tasse Kaffee und lassen Sie uns den Schwung beibehalten!
Wie immer, wenn Sie mehr erfahren möchten, lesen Sie die offizielle Google-Dokumentation über Robots-Meta-Tags und Header, um mehr zu erfahren.
Erstellen und Implementieren einer robots.txt-Datei
Die Erstellung und Implementierung einer robots.txt-Datei kann einschüchternd wirken, vor allem, wenn Sie nicht besonders technikaffin sind. Aber keine Panik! Wir stehen Ihnen bei jedem Schritt zur Seite. Wir werden diesen Prozess so einfach wie möglich gestalten, indem wir ihn in einfache Schritte unterteilen.
Erstellen Sie eine Datei und nennen Sie sie Robots.txt
Beginnen Sie mit der Erstellung einer neuen Textdatei. Dies können Sie mit einem einfachen Texteditor wie Notepad (Windows) oder TextEdit (Mac) tun. Sobald Sie ein leeres Dokument geöffnet haben, speichern Sie die Datei als robots.txt. Achten Sie darauf, dass alles klein geschrieben ist, denn Robots.txt, ROBOTS.TXT oder eine andere Großschreibung wird nicht erkannt.
Fügen Sie der Datei Robots.txt Direktiven hinzu
Überlegen Sie, was Sie zulassen oder verbieten wollen, und fangen Sie an, auf dieser Grundlage Direktiven einzugeben. Hier ist ein sehr einfaches Beispiel:
Benutzer-Agent: *
Nicht zulassen: /privat/
Dies weist alle Bots (aufgrund des Platzhalters *) an, nichts unter dem Verzeichnis /private/ zu crawlen.
Hochladen der Datei Robots.txt
Sobald Ihre robots.txt-Datei fertig ist, müssen Sie sie in das Stammverzeichnis Ihrer Website hochladen. Denken Sie daran, dass die robots.txt-Datei im Stammverzeichnis (z. B. www.yourwebsite.com/robots.txt) abgelegt werden muss, damit sie von den Bots gefunden und erkannt wird.
So finden Sie eine robots.txt-Datei
Um zu sehen, ob eine robots.txt-Datei vorhanden ist, geben Sie einfach /robots.txt am Ende der Haupt-URL Ihrer Website in Ihren Webbrowser ein.
Testen Sie Ihre Robots.txt
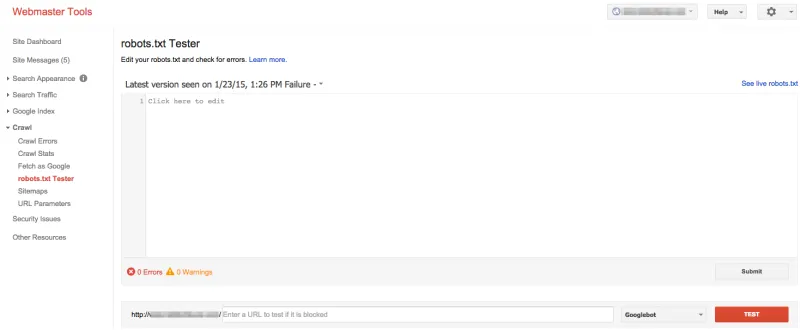
Schließlich ist es sehr empfehlenswert, Ihre robots.txt-Datei zu testen, um sicherzustellen, dass sie wie erwartet funktioniert. SEOmator bietet ein großartiges Robots.txt-Tester-Tool, das Sie bequem nutzen können.
Herzlichen Glückwunsch zur Erstellung Ihrer ersten robots.txt-Datei! Sie sind nun offiziell auf dem Weg, diese wichtige Seite der Website-Verwaltung und SEO zu meistern.
Und denken Sie daran: Je mehr Sie lernen, desto besser werden Ihre SEO-Fähigkeiten insgesamt sein. Scheuen Sie sich also nicht, sich selbst herauszufordern. Denn wie man so schön sagt: Lernen erschöpft den Geist nicht. Machen Sie weiter!
Einblick in die Robots.txt Best Practices
Nachdem Sie nun wissen, wie Sie eine robots.txt-Datei erstellen und implementieren können, sollten Sie dieses Wissen mit einigen wichtigen Best Practices verfeinern. Damit stellen Sie sicher, dass Sie nicht nur die Regeln befolgen, sondern dies auch effektiv tun.
Also schnallen Sie sich an, liebe Leserin, lieber Leser, während wir uns in das Universum der bewährten Verfahren von robots.txt begeben. Die Beherrschung von robots.txt steht vor der Tür!
Blockieren Sie keine CSS- und JS-Dateien in Robots.txt
Eine wichtige Erkenntnis für die optimale Nutzung Ihrer robots.txt-Datei ist die Vermeidung der Sperrung von JavaScript- und CSS-Dateien. Diese Dateien sind für Googlebots unerlässlich, um den Inhalt und die Struktur Ihrer Website effektiv zu verstehen.
Früher wurde das Blockieren solcher Dateien nicht als Problem angesehen, aber da Googlebots sich weiterentwickelt haben, um Seiten mehr wie ein menschlicher Besucher zu rendern, benötigen sie jetzt Zugang zu diesen Dateien, um die Analyse der Webseite zu verbessern.
Das Hinzufügen von CSS- oder JS-Dateien zur Disallow-Direktive könnte zu suboptimalen Rankings führen, da Google Ihr Seitenlayout oder die interaktiven Elemente möglicherweise nicht vollständig versteht. Denken Sie also daran: Lassen Sie die Bots die JavaScript- und CSS-Party auf Ihrer Website genießen!
Verwenden Sie getrennte Robots.txt-Dateien für verschiedene Subdomains
Wenn Ihre Website mehrere Subdomains hat, müssen Sie daran denken, dass jede Subdomain ihre eigene robots.txt-Datei benötigt. Wenn Sie beispielsweise einen Blog auf einer Subdomain haben (wie blog.ihrewebsite.com), benötigen Sie eine separate robots.txt-Datei unter blog.ihrewebsite.com/robots.txt.
Dies liegt daran, dass Suchmaschinen-Crawler Subdomains als separate Websites behandeln. Wenn Sie dieses Detail übersehen, kann dies zu Missverständnissen bei den Bots führen, die möglicherweise Bereiche Ihrer Website entgegen Ihren Absichten crawlen oder nicht crawlen.
Bewährte SEO-Praktiken für Robots.txt
Im großen Schema der Suchmaschinenoptimierung spielt Ihre robots.txt-Datei eine entscheidende Rolle. Im Folgenden finden Sie einige SEO-bezogene Best Practices für robots.txt:
Vermeiden Sie die vollständige Sperrung von Suchmaschinen: Das Blockieren aller Suchmaschinen-Bots kann dazu führen, dass Ihre Website überhaupt nicht indiziert wird. Verwenden Sie Disallow mit Bedacht und nur für bestimmte Teile Ihrer Website, die nicht indiziert werden sollen.
Verwenden Siees nicht zum Entfernen von URLs: Wenn Sie möchten, dass eine URL aus den Suchmaschinenergebnissen entfernt wird, ist die Verwendung von robots.txt, um diese URL zu verbieten, nicht der beste Weg, da sie aufgrund von externen Links, die auf sie verweisen, immer noch in den Ergebnissen erscheinen kann. Verwenden Sie stattdessen Methoden wie "noindex", "remove URLs tool" oder Passwortschutz.
Verlinken Sie auf Ihre XML-Sitemap: Eine ausgezeichnete Praxis ist die Verwendung von robots.txt, um auf Ihre XML-Sitemap zu verlinken. Dies erhöht die Wahrscheinlichkeit, dass Bots Ihre Sitemap finden und somit Ihre Seiten schneller indexieren.
Die Anwendung dieser bewährten Verfahren stellt sicher, dass Ihre robots.txt-Datei Ihren SEO-Strategien hilft und nicht im Wege steht.
Herzlichen Glückwunsch, lieber Leser! Sie haben einige der fortgeschritteneren Aspekte von robots.txt-Dateien kennengelernt. Bleiben Sie enthusiastisch, bleiben Sie neugierig, und lassen Sie uns diesen umfassenden Leitfaden über robots.txt abschließen!
Und wie immer gilt: Wenn Sie noch mehr Informationen und Anleitungen benötigen, sollten Sie sich die offiziellen Ressourcen von Google ansehen. Viel Spaß beim Lesen!
Schlussfolgerung: Die integrale Rolle von robots.txt in der SEO
Unsere Reise in die Tiefen von robots.txt bringt uns zu den abschließenden Gedanken. Sie haben erfahren, was robots.txt ist, wie wichtig sie ist, wie sie funktioniert, welche Richtlinien und Syntax sie hat und wie sie erstellt und implementiert wird. Wir haben auch praktische Anwendungen und bewährte Verfahren behandelt.
Lassen Sie uns nun die wichtigsten Punkte wiederholen und die Vor- und Nachteile der Verwendung von robots.txt, ihre Auswirkungen auf Ihr Crawl-Budget und Ihre Suchmaschinenoptimierung sowie die absehbaren zukünftigen Richtungen bei der Verwendung von robots.txt betrachten.
Vor- und Nachteile der Verwendung von robots.txt
Wie bei allen Optimierungsstrategien gibt es auch bei robots.txt Vorteile und potenzielle Fallstricke:
Vorteile:
-
Kontrolle über das Crawling: robots.txt gibt Ihnen eine einfache Möglichkeit, Bots anzuweisen, wohin sie auf Ihrer Website gehen sollen und wohin nicht.
-
Crawl-Budget-Optimierung: Es ermöglicht die effiziente Nutzung Ihres Crawl-Budgets, indem es die Crawler zu den wichtigen Bereichen Ihrer Website lenkt.
-
Vermeidung der Indizierung nicht-öffentlicher Bereiche: Sie können verhindern, dass bestimmte Bereiche Ihrer Website indiziert werden.
Nachteile:
-
Nicht rechtlich bindend: Bots können Ihre robots.txt ignorieren - insbesondere Malware-Bots, die Ihre Website nach Schwachstellen durchsuchen.
-
Kann zu Crawlability-Problemen führen: Bei falscher Konfiguration können Sie Bots versehentlich daran hindern, Ihre Website zu crawlen.
Die Auswirkungen von robots.txt auf Crawl-Budget und SEO
Eine gut strukturierte robots.txt-Datei hat einen tiefgreifenden Einfluss auf das Crawl-Budget und die Suchmaschinenoptimierung Ihrer Website. Indem Sie es den Crawlern ermöglichen, sich auf die Bereiche Ihrer Website zu konzentrieren, die die meiste Aufmerksamkeit verdienen, tragen Sie dazu bei, dass Ihre Website effektiv und effizient gecrawlt wird, und maximieren so die Chance auf höhere Rankings.
Zukünftige Richtungen bei der Verwendung von Robots.txt
Die Robots-Richtlinie von Google entwickelt sich ständig weiter und strebt nach besserer Verständlichkeit und umfassenderer Abdeckung. Für die Zukunft erwarten wir eine präzisere Syntax, bessere Richtlinien, verbesserte Unterstützung für internationale URLs und ein immer besseres Verständnis der Bedürfnisse von Website-Betreibern.
Puh! Sie haben es geschafft! Sie beherrschen jetzt die robots.txt und sind bereit, Ihre Website für ein reibungsloses Crawling und die Indizierung durch Suchmaschinen-Bots zu optimieren.
Herzlichen Glückwunsch, lieber Leser, dass Sie es bis zum Ende dieser umfassenden robots.txt-Anleitung geschafft haben. Ihre Entschlossenheit, Ihre Bereitschaft zu lernen und Ihr neu erworbenes Wissen über robots.txt-Dateien werden Ihre SEO-Bemühungen sicherlich zu neuen Höhen führen.
Denken Sie daran: Wissen ist Macht, und Sie sind gerade noch mächtiger geworden! Gute Arbeit und weiter so!
P.S.: Hat Ihnen Ihre Reise gefallen? Erforschen Sie weiter. SEO ist ein riesiger Ozean, und es gibt immer mehr zu lernen!
Sie können auch lesen:






