Pagination in SEO is the practice of splitting large sets of content across multiple numbered pages to help search engines crawl and index each page individually while improving user navigation. According to Lumar's analysis of the top 150 e-commerce sites, 65% use non-search-engine-friendly pagination practices, with 30-50% of their content blocked from indexing as a result. Proper pagination implementation uses self-referencing canonical tags, clean URL structures, and strategic internal linking to maintain crawl efficiency and preserve link equity across paginated series.
Pagination is the method of dividing content into discrete, numbered pages connected by navigation links. You encounter pagination on e-commerce category pages, blog archives, forum threads, and search results pages where content is too extensive to display on a single URL.
From an SEO perspective, pagination creates multiple URLs that search engines must crawl and evaluate independently. Each paginated page (page 2, page 3, and so on) is a separate URL with its own content, and how you structure these pages directly affects your site's crawl budget, indexation coverage, and link equity distribution.
Google deprecated the rel="next" and rel="prev" markup in March 2019, meaning search engines no longer use these tags to understand paginated sequences. According to Search Engine Land, Google had quietly stopped supporting these signals years earlier without informing the SEO community. This deprecation shifted pagination SEO strategy toward proper canonical tags, clean URL structures, and internal linking patterns.
What Are the Benefits and Risks of Pagination for SEO?
Pagination offers clear advantages when implemented correctly, but creates significant SEO problems when handled poorly. According to research from Avatria, 73% of e-commerce category page users never visit page 2, and over 89% never visit the second page of search results. This means pagination structure directly impacts whether your deeper content gets discovered at all.
| Aspect | Benefits | Risks |
|---|
| Crawl Efficiency | Smaller pages load faster, reducing server strain during crawls | Deep pagination consumes crawl budget on low-value pages |
| Content Indexation | Each page can target specific content segments | Duplicate content issues if pages share similar titles or descriptions |
| Link Equity | Internal links between pages distribute authority | Link equity dilutes across many paginated URLs |
| User Experience | Breaks content into digestible sections | Excessive clicking frustrates users seeking specific items |
| Page Speed | Smaller page payloads load faster | Additional HTTP requests for navigation elements |
- Faster page load times: Distributing content across multiple pages reduces individual page weight. For e-commerce sites with thousands of products, this prevents category pages from becoming slow and unresponsive.
- Improved crawl accessibility: Search engine bots can process smaller pages more efficiently. Each paginated page presents a manageable set of content for indexing rather than forcing bots to parse extremely long pages.
- Better content targeting: Each paginated page can surface different products or articles, giving search engines more specific content to evaluate and potentially rank for long-tail queries.
- Increased page views: Users navigating through paginated series generate additional pageviews, creating more opportunities for engagement, ad impressions, and conversion touchpoints.
- Duplicate content problems: Paginated pages often share identical page titles, meta descriptions, and boilerplate content. Search engines may treat these as duplicate pages, causing cannibalization where your own pages compete against each other in search results.
- Crawl budget waste: According to Google's crawl budget documentation, large paginated archives can generate thousands of URLs that consume crawl resources. Search engines may spend their crawl budget on page 200 of a forum thread instead of your most valuable content.
- Diluted link equity: External links pointing to page 1 of a paginated series do not automatically pass authority to pages 2 through 50. This concentration of link equity on the first page weakens deeper paginated content.
- Poor user experience: Poorly designed pagination with unclear navigation, broken links between pages, or inconsistent content ordering leads to high bounce rates and reduced engagement.
What Is the Difference Between Pagination and Infinite Scroll?

Pagination and infinite scroll are the two primary methods for presenting large content sets, and each has distinct implications for SEO and user behavior.
| Feature | Pagination | Infinite Scroll |
|---|
| URL Structure | Each page has a unique, crawlable URL | Single URL loads content dynamically via JavaScript |
| Search Engine Crawling | Bots crawl each page independently | Bots may miss content loaded after initial page render |
| Content Discoverability | All pages are discoverable through internal links | Content below the fold may not be indexed |
| User Navigation | Users can jump to specific pages or bookmark locations | Users cannot easily return to a specific position |
| Page Speed | Consistent load times per page | Performance degrades as more content loads |
| Best Use Case | E-commerce categories, blog archives, search results | Social media feeds, image galleries, news streams |
Google recommends pagination over infinite scroll for content that needs to be indexed. According to Google's e-commerce pagination documentation, paginated pages with distinct URLs allow Googlebot to crawl and index each page individually. Infinite scroll implementations require additional technical work (such as replicated paginated pages) to ensure search engines can access all content.
Implementing pagination correctly requires attention to canonical tags, URL structure, internal linking, and crawl directives. These seven practices address the most common pagination SEO issues.
1. Self-Canonicalize Each Paginated Page
Every paginated page should include a self-referencing canonical tag that points to its own URL. This tells search engines that each page is intentional and unique, preventing them from consolidating paginated pages into a single URL.
Do not point canonical tags from page 2, 3, or 4 back to page 1. This common mistake tells search engines to ignore the content on deeper pages entirely, which defeats the purpose of pagination.
2. Use Clean, Descriptive URLs
Paginated URLs should clearly indicate the page number and content type. Avoid query parameters with ambiguous values and fragment identifiers that search engines may ignore.
| URL Type | Example | SEO Impact |
|---|
| Clean (recommended) | example.com/blog/page/2 | Crawlable, user-friendly, clearly indicates page position |
| Parameter-based | example.com/blog?page=2 | Crawlable but less readable, may cause duplicate issues |
| Fragment identifier (avoid) | example.com/blog#page2 | Not crawled by search engines, content invisible to bots |
URL fragments (the part after #) are not sent to servers and are not crawled by search engines. Content accessible only through fragment identifiers will not be indexed. Always use server-side pagination with distinct URLs for each page.
4. Optimize Only the First Page in a Series
Focus your keyword optimization efforts on page 1 of each paginated series. Deeper pages should have unique but de-optimized titles and descriptions to avoid keyword cannibalization. For example, page 2 of a product category could use the format "Category Name - Page 2" rather than repeating the primary keyword-rich title.
5. Do Not Noindex Paginated Pages
Adding noindex to paginated pages prevents search engines from indexing the content on those pages, but more importantly, it can cause Google to stop following links on those pages over time. This means products or articles only accessible through deeper paginated pages may become invisible to search engines entirely.
Instead of noindex, use self-referencing canonical tags and ensure each page provides unique, valuable content that justifies its existence in the index.
6. Build Strong Internal Linking Between Pages
Each paginated page should link to the previous and next pages in the series, plus include links to the first and last pages. This creates a clear crawl path that search engines can follow to discover all content in the series.
For deep paginated series with hundreds of pages, add intermediate page links (such as page 1, 5, 10, 20, 50, 100) to reduce the number of clicks needed to reach any specific page. This pattern helps both users and search engine bots navigate large content sets efficiently.
Use Google Search Console's indexing reports to verify that paginated pages are being discovered and indexed. Check the "Pages" report under "Indexing" to identify any paginated URLs that are excluded, crawled but not indexed, or flagged with errors.
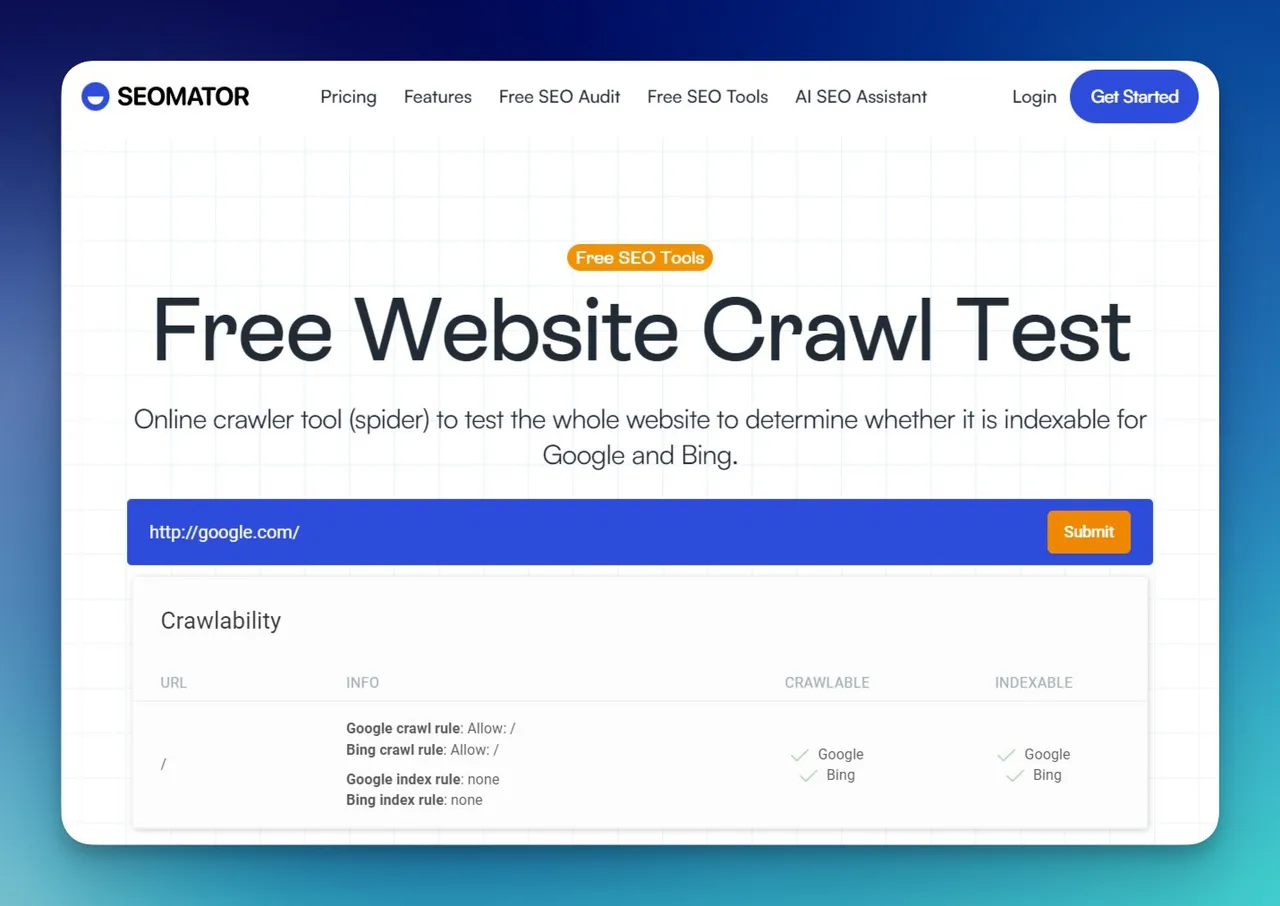
Use SEOmator's Free Website Crawl Test to check whether your paginated pages are accessible to search engine crawlers. The tool identifies crawl errors, blocked URLs, and indexation issues that may affect your paginated content. For a comprehensive technical SEO review, consider running a full SEO audit that evaluates your entire site structure including pagination implementation.
Key Takeaways
- Pagination splits large content sets across numbered pages with unique URLs, allowing search engines to crawl and index each page individually.
- Google deprecated rel="next" and rel="prev" in March 2019. Modern pagination SEO relies on self-referencing canonical tags, clean URLs, and internal linking.
- According to Lumar, 65% of top e-commerce sites use non-SEO-friendly pagination, blocking 30-50% of their content from search engine indexing.
- Each paginated page should self-canonicalize to its own URL. Never point canonical tags from deeper pages back to page 1.
- Avoid noindexing paginated pages, as this can cause search engines to stop following links on those pages entirely.
- Pagination is preferred over infinite scroll for SEO because each paginated page has a distinct, crawlable URL that search engines can index independently.
Related Articles
Frequently Asked Questions
Does Google still support rel="next" and rel="prev" for pagination?
Google officially deprecated rel="next" and rel="prev" in March 2019 and confirmed that these tags had not been used as indexing signals for several years before the announcement. Modern pagination SEO should focus on self-referencing canonical tags, clean URL structures, and proper internal linking rather than relying on these deprecated attributes.
Should you noindex paginated pages?
No. Adding noindex to paginated pages prevents search engines from indexing the content on those pages and can eventually cause Google to stop following links on noindexed pages. This means products or content only accessible through deeper paginated pages may become completely invisible to search engines. Use self-referencing canonical tags instead.
Pagination is better for SEO because each paginated page has a unique, crawlable URL that search engines can discover and index independently. Infinite scroll loads content dynamically via JavaScript, which search engines may not process completely. Google recommends using pagination with distinct URLs for content that needs to appear in search results.
Each paginated page consumes a portion of your site's crawl budget because search engines must request and process each URL individually. Large paginated archives with thousands of pages can consume significant crawl resources. Optimize crawl budget by ensuring paginated pages contain unique, valuable content and by using internal linking patterns that help search engines reach important pages within fewer clicks.
What is the correct canonical tag for paginated pages?
Each paginated page should have a self-referencing canonical tag that points to its own URL. For example, page 2 should have a canonical tag pointing to the page 2 URL, not back to page 1. Pointing all canonical tags to page 1 tells search engines to ignore the content on deeper pages, effectively hiding that content from search results.



