Extracting text from a website means programmatically or manually retrieving specific text content from HTML pages for analysis, research, or content creation purposes. According to Mordor Intelligence, the global web scraping market reached $1.03 billion in 2025 and is projected to grow to $2.00 billion by 2030 at a 14.2% CAGR, reflecting the increasing demand for automated data extraction across industries. Python dominates web scraping with nearly 70% usage among practitioners, while frameworks like Beautiful Soup (43.5%) and Selenium (26.1%) remain the most popular tools for parsing and extracting web content.
Website text extraction is the process of isolating readable text content from the HTML code that structures a web page. HTML uses tags like <p>, <h1> through <h6>, <a>, and <li> to define content elements. Text extraction targets the content within these tags while stripping away the surrounding markup, styling, and scripts.
| HTML Element | Tag | What It Contains | Extraction Use Case |
|---|
| Paragraphs | <p> | Body text and main content | Article content, product descriptions, reviews |
| Headings | <h1> to <h6> | Section titles and subtitles | Content structure analysis, topic identification |
| Anchor Text | <a> | Clickable link text with URLs | Link analysis, competitor backlink research |
| List Items | <li> | Bulleted or numbered list content | Feature lists, product specifications, FAQs |
| Table Cells | <td>, <th> | Structured tabular data | Price comparisons, specifications, statistics |
The complexity of text extraction depends on the website's structure. Static HTML pages with clean markup are straightforward to parse. Dynamic websites that load content via JavaScript require more advanced techniques, as the text may not exist in the initial HTML source code.
Text extraction serves multiple business and research purposes. The growing web scraping market, projected to expand at 14.2% annually through 2030, reflects the increasing value organizations place on structured web data.
| Use Case | What You Extract | Business Value |
|---|
| SEO Analysis | Title tags, headings, meta descriptions, anchor texts | Identify optimization opportunities and content gaps |
| Competitor Research | Product descriptions, pricing, feature lists | Understand competitor positioning and strategy |
| Content Aggregation | Article text, publication dates, author names | Build topic-specific databases for research |
| Market Intelligence | Customer reviews, ratings, sentiment data | Track brand perception and product feedback |
| Link Building Research | External links, anchor text patterns, referring domains | Find link opportunities and analyze backlink profiles |
For SEO practitioners, text extraction is particularly valuable for auditing website content at scale. Rather than manually reviewing hundreds of pages, extraction tools can pull all headings, meta descriptions, and internal links into a structured format for analysis. Use SEOmator's Free Anchor Text and Link Extractor to extract all external and internal links along with their corresponding anchor texts from any web page.
What Are the 3 Main Methods to Extract Text from a Website?
Each extraction method suits different scenarios based on the volume of data, technical requirements, and website complexity. Choose the approach that matches your specific needs and skill level.
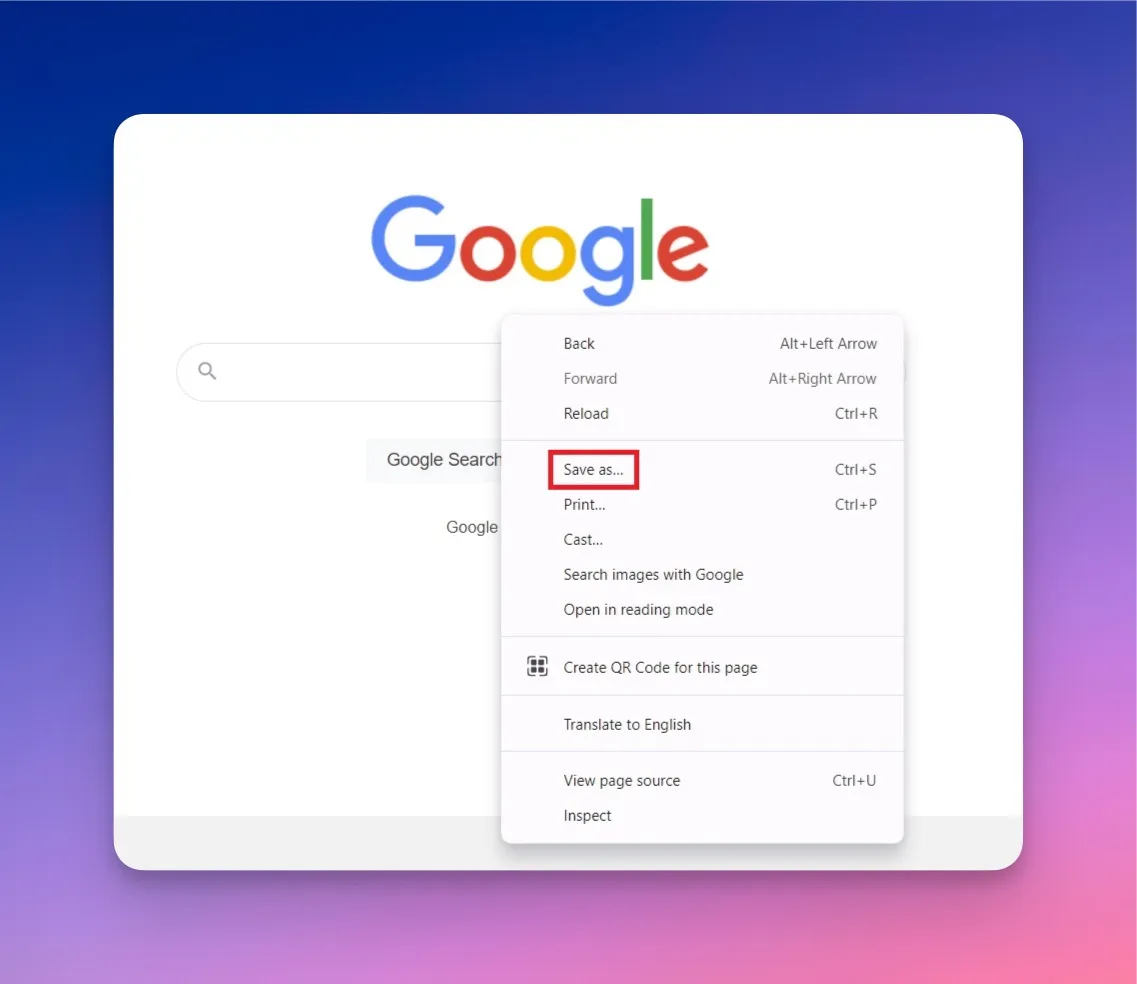
Manual extraction works for small-scale tasks where you need text from a few specific pages. Select the text you want with your mouse, copy it using Ctrl+C (Windows) or Command+C (macOS), and paste it into your target document.
For extracting all visible text from a page, most browsers allow you to save the page as an HTML file or plain text file through the "Save As" option in the right-click menu. This captures the full page content without requiring any technical tools.
Manual extraction becomes impractical for projects involving more than a handful of pages. Copying text from 50 or more pages is time-consuming, error-prone, and does not scale for ongoing data collection needs.

Dedicated tools and programming libraries handle text extraction more efficiently than manual methods. These range from no-code browser extensions to Python libraries that require basic coding knowledge.
| Tool | Type | Best For | Technical Skill Required |
|---|
| Beautiful Soup | Python library | Parsing HTML and XML documents with precise element targeting | Basic Python knowledge |
| Selenium | Browser automation | Extracting text from JavaScript-rendered dynamic pages | Intermediate programming |
| Web Scraper | Browser extension | Setting up extraction workflows directly in Chrome | No coding required |
| Import.io | Cloud platform | Converting web pages into structured datasets | No coding required |
Beautiful Soup remains the most popular extraction library, used by 43.5% of web scraping practitioners according to industry surveys. It excels at navigating HTML parse trees and extracting content from specific tags, attributes, or CSS selectors. A basic Beautiful Soup script can extract all paragraph text from a page in fewer than 10 lines of Python code.
For websites that load content dynamically through JavaScript, tools like Selenium or Playwright (used by 26.1% of practitioners) render the page in a real browser before extracting the visible text, capturing content that static HTML parsers cannot access.
3. Automated Web Scraping at Scale
Automated web scraping uses programmed bots to navigate websites and extract text from multiple pages systematically. This approach handles large-scale extraction tasks that would take hours or days to complete manually.
Web scraping bots follow a defined set of instructions: visit a URL, locate specific HTML elements, extract the text content, store it in a structured format, then move to the next page or URL. This process can extract text from thousands of pages in minutes.
| Scraping Tool | Key Feature | Pricing |
|---|
| ParseHub | Visual point-and-click interface for dynamic and AJAX websites | Free tier available |
| Octoparse | No-code scraping with cloud-based processing and scheduling | Free tier available |
| Scrapy | Python framework for building custom large-scale crawlers | Open source |
AI-powered extraction tools are the fastest-growing segment in this space. According to market research, AI delivers 30 to 40% faster extraction with up to 99.5% accuracy and adapts automatically to website layout changes that would break traditional scraping scripts.
Text extraction raises legal and ethical considerations that you should address before starting any extraction project.
- Robots.txt compliance: Check the target website's robots.txt file to see which pages allow automated access. Respecting these directives is both ethical and helps avoid IP blocks.
- Terms of service: Many websites explicitly prohibit automated scraping in their terms of service. Review these terms before extracting data to avoid legal issues.
- Rate limiting: Sending too many requests too quickly can overload a server. Implement delays between requests and respect any rate limits the website enforces.
- Copyright and fair use: Extracted text may be protected by copyright. Using extracted content for analysis or research is generally acceptable, but republishing it as your own content is not.
- Personal data: If the extracted text contains personal information, data protection regulations like GDPR may apply to how you store and use that data.
For a comprehensive analysis of your own website's text content, link structure, and SEO elements, run a free SEO audit to identify optimization opportunities across all your pages.
Key Takeaways
- Website text extraction isolates readable content from HTML markup for analysis, research, and content creation, with the global web scraping market reaching $1.03 billion in 2025.
- Three main methods exist: manual copy-paste for small tasks, online tools and libraries for moderate needs, and automated web scraping for large-scale extraction across thousands of pages.
- Python dominates text extraction with 70% usage, and Beautiful Soup remains the most popular parsing library at 43.5% adoption among practitioners.
- AI-powered extraction tools deliver 30 to 40% faster extraction with up to 99.5% accuracy, representing the fastest-growing segment in web scraping technology.
- Always check robots.txt files, terms of service, and copyright considerations before extracting text from any website to ensure legal and ethical compliance.
- For SEO analysis, text extraction enables auditing headings, meta descriptions, anchor texts, and internal links at scale rather than reviewing pages manually one by one.
Related Articles
Frequently Asked Questions
Text extraction legality depends on the website's terms of service, the type of data being extracted, and your intended use. Extracting publicly available information for analysis or research is generally acceptable in most jurisdictions. However, violating a website's terms of service, ignoring robots.txt directives, or extracting copyrighted content for republication can create legal risks. Always review the target site's terms and applicable data protection laws before starting any extraction project.
The best tool depends on your technical skill level and the scale of extraction needed. Beautiful Soup is the most popular choice for developers, used by 43.5% of web scraping practitioners, because it offers precise control over HTML parsing with relatively simple Python code. For non-technical users, browser extensions like Web Scraper or cloud platforms like Octoparse provide visual interfaces that require no coding. For dynamic JavaScript-heavy sites, Selenium or Playwright are necessary to render content before extraction.
Yes, but dynamic websites require different tools than static HTML pages. When a site loads content through JavaScript after the initial page load, static HTML parsers like Beautiful Soup cannot access that content because it does not exist in the raw HTML source. Browser automation tools like Selenium and Playwright solve this by running a full browser that executes JavaScript and renders the complete page, allowing you to extract all visible text regardless of how it was loaded.
There is no technical limit to how much text you can extract, but practical limits exist. Website rate limiting may restrict how many pages you can access per minute. Server resources can be strained by excessive requests. Most automated tools can extract text from hundreds to thousands of pages per hour when properly configured with appropriate delays between requests. For very large extraction projects involving millions of pages, cloud-based scraping services with distributed infrastructure offer the most reliable performance.
What is the difference between web scraping and text extraction?
Text extraction is one specific type of web scraping. Web scraping is the broader practice of automatically collecting any data from websites, which can include images, prices, product information, links, and structured data. Text extraction specifically focuses on retrieving the readable text content from web pages, typically from HTML elements like paragraphs, headings, and list items. All text extraction from websites is web scraping, but not all web scraping is text extraction.



