Did you know that the average website has 25% more pages than its owners realize? I've audited over 200 websites in my SEO career, and hidden pages - orphans, duplicates, and forgotten test pages - are one of the most common issues I see draining crawl budget and confusing search engines.
Finding all pages on a website isn't just a technical exercise. It's the foundation of effective SEO. Whether you're conducting a site audit, planning a redesign, or analyzing a competitor, knowing exactly what pages exist gives you the complete picture you need to make smart decisions.
In this guide, I'll walk you through every method I use to uncover pages - from quick Google searches to command-line tools that reveal what crawlers miss. You'll learn which approach works best for different scenarios and what to do once you've mapped your site's full inventory.

Why Finding Every Page Matters for SEO
You might wonder if this matters for smaller sites. After all, don't you already know what's on your website? In my experience, the answer is almost always no - at least not completely.
According to Botify's research, search engines don't crawl up to 50% of pages on large websites. For mid-sized sites, that number drops but orphan pages and crawl inefficiencies remain common. Here's why a complete page inventory matters:
Orphan Pages Waste Your Content Investment

Orphan pages have no internal links pointing to them. They're essentially invisible to both users and search engines. I recently audited a site where 15% of their blog posts were orphaned - that's valuable content that wasn't ranking because Google couldn't find it through normal crawling.
When you identify orphans, you can integrate them into your site structure with strategic internal links, immediately improving their discoverability.
Odd-Ranking Pages Need Re-optimization
Sometimes you'll find pages ranking for keywords they weren't optimized for. These "odd rankers" represent quick wins. With minor content adjustments, you can align them with user intent and boost their positions.
Duplicate Content Dilutes Your SEO Efforts
Duplicate pages compete with each other for rankings, splitting link equity and confusing search engines about which version to show. A complete inventory reveals these duplicates so you can consolidate them with canonical tags or 301 redirects.
Site Architecture Insights Power Better Redesigns

Planning a redesign without knowing your full site structure is like renovating a house without blueprints. When you map every page, you can plan URL migrations properly, preserve SEO equity, and design a navigation that actually reflects your content.
Internal Linking Strategy Depends on Page Inventory
According to Ahrefs' analysis of 23,000 websites, proper internal linking is one of the most underutilized SEO techniques. You can't build an effective internal linking strategy without knowing what pages you have to link between.
Competitor Analysis Requires Full Visibility
This isn't just about your own site. Learning to find all pages on any website lets you analyze competitors' content strategies, identify gaps in your own coverage, and discover content opportunities they're targeting.
Quick Methods to Find All Pages
Let's start with the approaches that work for most situations. I use these daily when beginning any site audit.
Google's site: Search Operator
The fastest way to see what Google has indexed is the site: operator. Here's how to use it:
- Open Google and type
site:example.com (replace with your domain)
- Press Enter to see all indexed pages
- Add specific terms like
site:example.com blog to filter results

Limitation: This only shows indexed pages. Non-indexed pages, those blocked by robots.txt, or pages Google chose to ignore won't appear.
Check the Robots.txt File
The robots.txt file reveals what the site owner wants to hide from crawlers. Access it at example.com/robots.txt.
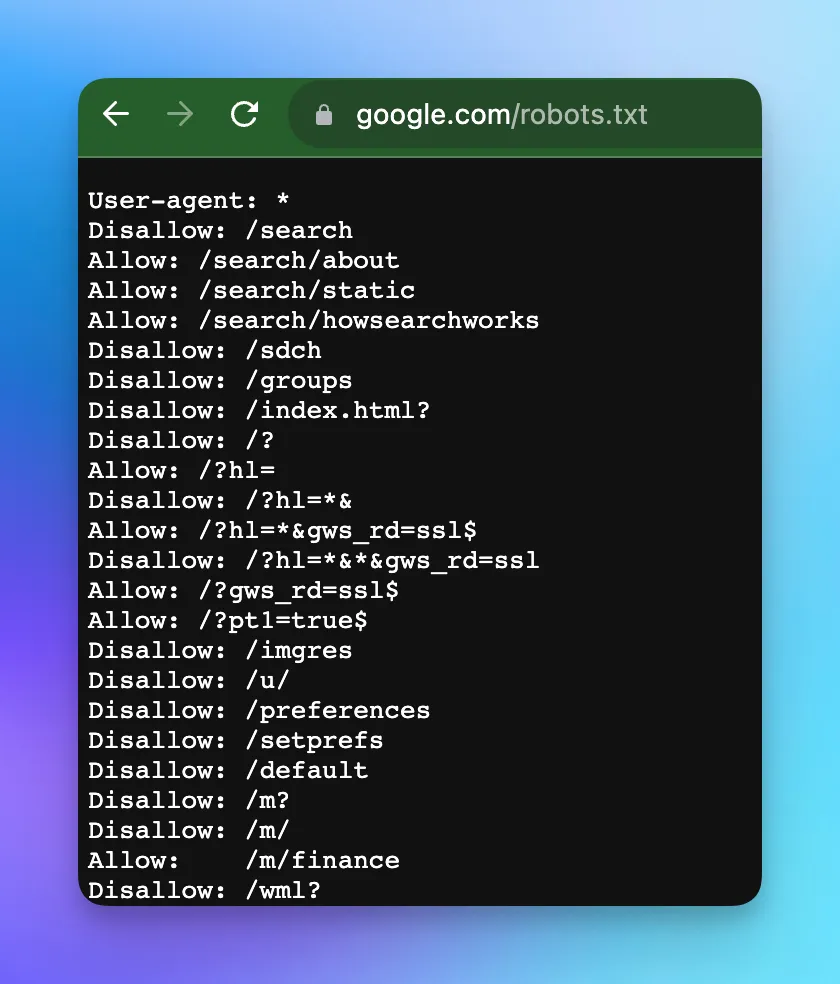
Look for Disallow: directives - these point to directories and pages hidden from search engines. While you won't find every page this way, you'll discover sections that other methods might miss.
Analyze the XML Sitemap
Sitemaps are designed to list all important pages. Check example.com/sitemap.xml or use SEOmator's Sitemap Finder to locate it.
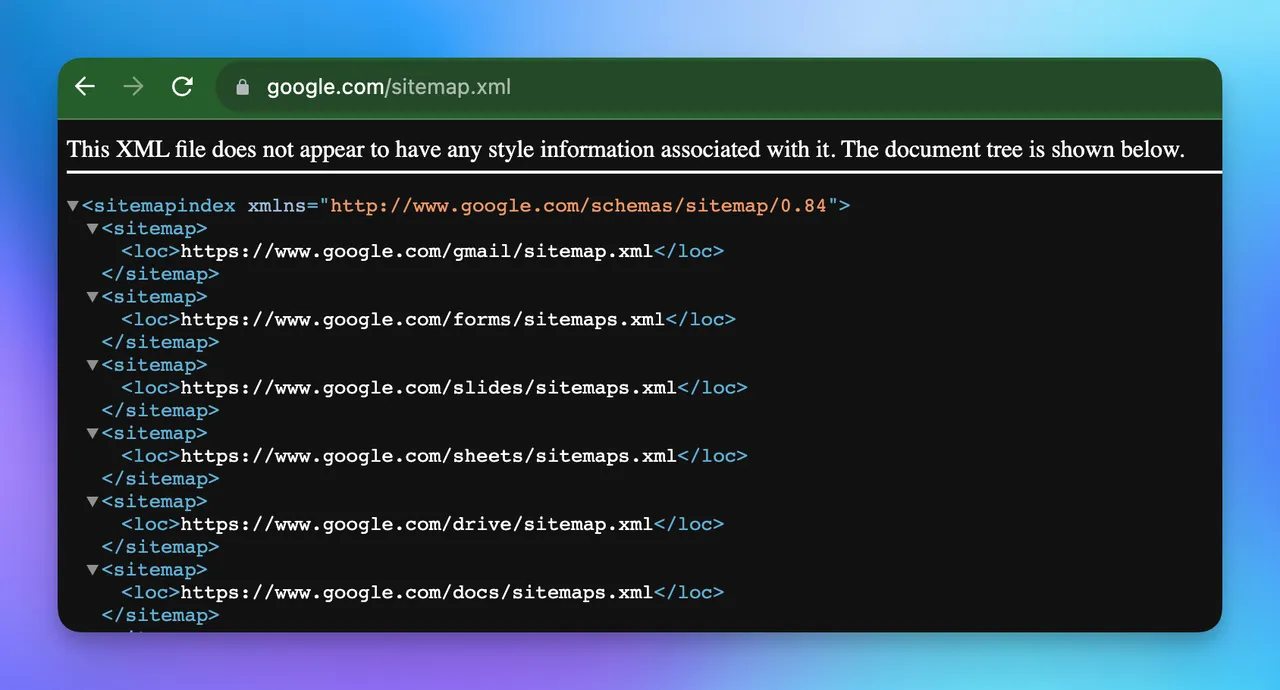
Well-maintained sitemaps provide a clean list of pages the site owner wants indexed. However, I've found that sitemaps are often outdated or incomplete, so don't rely on them exclusively.
Tools like Screaming Frog or Lumar (formerly DeepCrawl) crawl websites the same way search engines do. They start from the homepage and follow every internal link, building a complete map of discoverable pages.
These tools are my go-to for comprehensive audits. They reveal:
- All linked pages (and orphans when compared to sitemaps)
- Response codes for each URL
- Page titles, meta descriptions, and headings
- Internal and external links
Pro tip: Run a crawl AND import your sitemap into the same project. Comparing the two datasets instantly reveals orphan pages.
Google Search Console
For sites you own or manage, Google Search Console provides the most authoritative view of how Google sees your site. Navigate to Pages under the Indexing section to see:
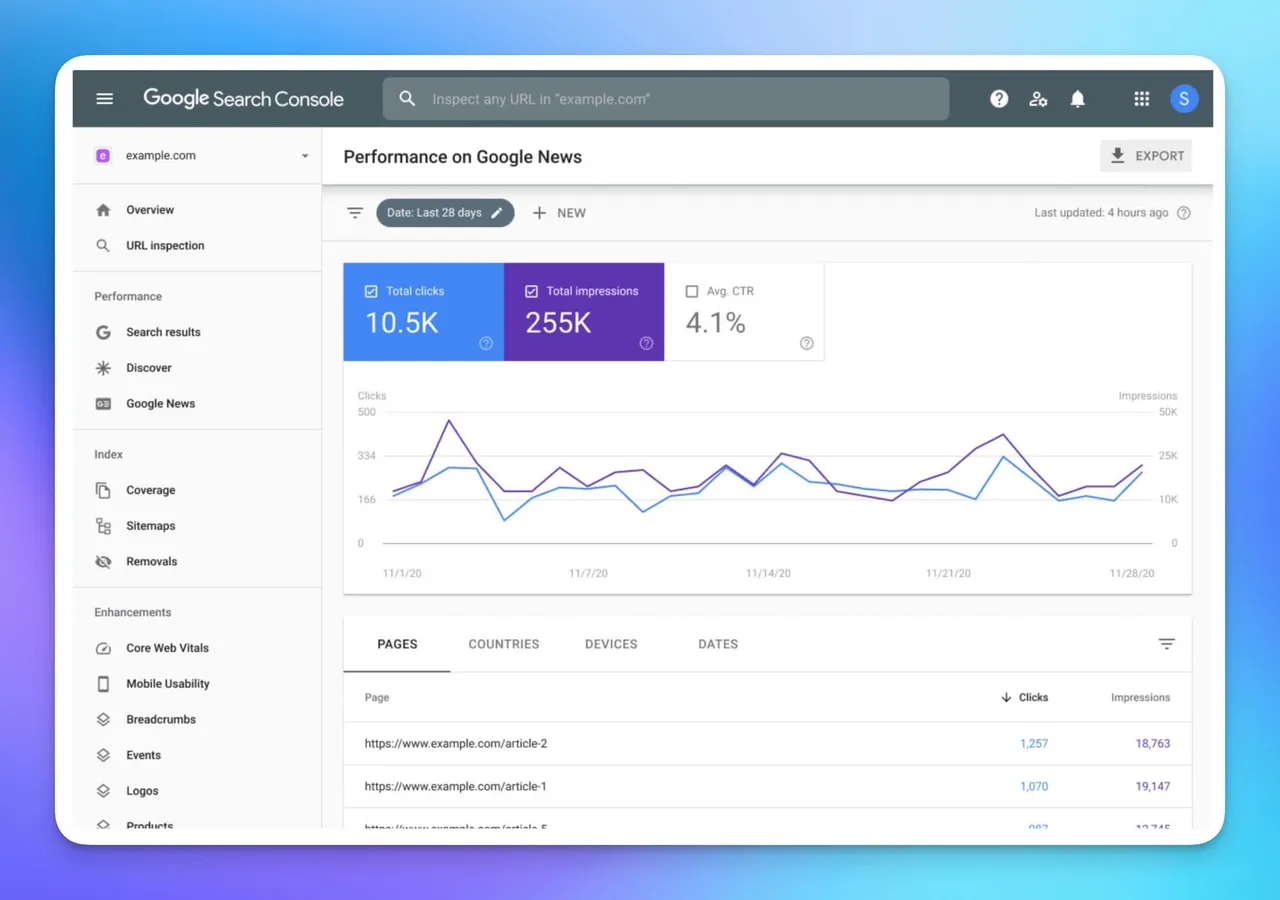
- Pages that are indexed and appearing in search
- Pages crawled but not indexed (and why)
- Pages excluded due to canonical, noindex, or robots.txt
This data comes directly from Google's crawl, making it invaluable for understanding your site's actual search visibility.
Google Analytics
If the site uses Google Analytics, check Reports > Engagement > Pages and screens to see which pages receive traffic. While this won't show zero-traffic pages, it reveals the pages that actually matter for user engagement.
Advanced Page Discovery Techniques
When basic methods aren't enough, these advanced approaches help uncover pages that slip through standard crawls.
For technical users, wget provides powerful crawling capabilities. Here's the command I use:
wget --spider --no-parent -r https://example.com
This recursively crawls the site and logs every URL it finds. The --spider flag means it won't download files, just record the links.
Requirements: wget comes pre-installed on Mac and Linux. Windows users can use WSL or install it via Chocolatey.
Server Log Analysis
Server logs record every request to your website, including requests from search engine bots. Analyzing these logs reveals:
- Pages Googlebot actually crawls (versus what you want crawled)
- Crawl frequency patterns
- 404 errors from broken links
- Hidden pages that bots discovered somehow
Tools like Screaming Frog Log File Analyser make parsing these logs manageable.
WordPress Plugins

WordPress sites can leverage plugins for page discovery:
- Yoast SEO generates comprehensive XML sitemaps
- The built-in Pages and Posts admin screens show all content
- Database export tools can extract every URL from the wp_posts table
CMS-Specific Features
Most content management systems provide page listings. Check your CMS documentation - whether it's Webflow, Shopify, Squarespace, or another platform - for built-in site inventory features.
Comprehensive SEO platforms like SEOmator, Semrush, and Ahrefs include site crawlers that map your pages while simultaneously checking for SEO issues. These tools combine discovery with actionable insights.
What to Do After Finding All Pages
Discovery is just the beginning. Here's my workflow for turning a page inventory into SEO improvements.
Segment Your Pages by Performance

I categorize pages into four buckets:
- High traffic, high conversion: Your winners - protect and enhance these
- High traffic, low conversion: Optimization opportunities - improve CTAs and UX
- Low traffic, high conversion: Hidden gems - increase visibility with internal links and promotion
- Low traffic, low conversion: Candidates for improvement or removal
Connect Orphan Pages
Add internal links from relevant pages to your orphans. This passes link equity and helps search engines discover the content. Contextual links within body content work better than footer or sidebar links.
Consolidate Duplicates
For duplicate content, decide which version should be canonical. Then either:
- Add
rel="canonical" tags pointing to the primary version
- Implement 301 redirects if the duplicate URLs can be removed
- Use
noindex on pages that need to exist but shouldn't rank
Refresh Outdated Content
According to Backlinko's ranking factors study, content freshness influences rankings for time-sensitive queries. Update statistics, remove outdated information, and add current best practices.
Build an Internal Linking Strategy
With your complete page inventory, create a linking plan that:
- Connects topically related pages
- Distributes link equity to priority pages
- Uses descriptive, keyword-rich anchor text
- Creates logical user pathways through your content
Set Up Ongoing Monitoring
Page inventory isn't a one-time task. Set quarterly reminders to re-crawl your site and compare results. New orphans, duplicates, and issues emerge as content grows.
Key Takeaways
- Start with multiple methods: No single technique catches everything - combine Google operators, sitemaps, and crawl tools
- Compare data sources: Sitemap vs. crawl comparisons instantly reveal orphan pages
- Use GSC for owned sites: Google Search Console shows how Google actually sees your pages
- Segment and prioritize: Not all pages deserve equal attention - focus on high-impact improvements
- Make it a habit: Regular audits catch issues before they compound

Mastering page discovery transforms how you approach SEO. Instead of guessing what's on your site, you'll have complete visibility into your content inventory. That visibility powers smarter decisions about optimization, content strategy, and site architecture.
The tools and techniques in this guide work for sites of any size. Start with the quick methods, add advanced techniques as needed, and build page auditing into your regular SEO workflow. Your rankings - and your sanity - will thank you.
Frequently Asked Questions
How often should I audit my website's pages?
For most sites, quarterly audits work well. Large sites with frequent content updates benefit from monthly crawls. Set up automated crawl schedules in tools like Screaming Frog to catch issues early.
What's the fastest way to find orphan pages?
Crawl your site with an SEO spider tool, then import your XML sitemap. Any URLs in the sitemap that weren't discovered during the crawl are likely orphans - they exist but have no internal links pointing to them.
Can I find pages on websites I don't own?
Yes, most methods work on any public website. Google's site: operator, sitemap checks, and third-party crawlers don't require site ownership. Server logs and CMS access obviously require permissions.
How do I find pages Google hasn't indexed?
Compare your crawl data with Google Search Console's indexed pages report. URLs that exist on your site but don't appear in GSC either weren't crawled, were crawled but not indexed, or are blocked. GSC tells you exactly why each page isn't indexed.
Additional Resources
The Art of SEO: Mastering Search Engine Optimization - Comprehensive guide covering crawling, indexation, and website architecture from Eric Enge, Stephan Spencer, and Jessie Stricchiola.
What is SEO? How Does It Work? - Beginner-friendly introduction to search engine optimization fundamentals.
Best CMS Platforms for SEO - Comparison of content management systems and their SEO capabilities.
Content Optimization: The Complete Guide - Learn how to optimize the pages you discover for better search rankings.



